왜 클라우드일까?
- 관리가 훨씬 쉽고, 보안이 뛰어나며, 가용성이 좋다
- 스파크를 쓸 때는 여러 대의 컴퓨터를 사용하는데, 실제 여러대의 컴퓨터르르 사용하는게 아닌, 보통 클라우드의 서버를 빌린다.
클라우드 3대장
1) AWS는 지금까지 시장을 지배해왔고, 앞으로도 그럴 가능성이 높다 .한 번 시장을 지배한 이후로, 모든 것의 기준이 되었다.
2) GCP는 Bigquery 원툴일 수 있지만, 그 원툴이 너무 강력
3) Azure는 편하지만, 비싸다.
그 외 여러 가지 이유(지원, 투자, 계열사 등)로 기타 클라우드를 사용하는 경우도 많다

클라우드 사용 이유 3가지
1) 스토리지
- AWS를 이용하게 되면 기본적으로 대부분의 파일(데이터)를 S3(Simple Storage Service)에 보관함
- 내 컴퓨터에 보관하는 것보다 안전하며, 임의의 팀원이 접근할 수 있다.
- 그 데이터를 다시 데이터베이스에 연결하여 사용할 수도 있다.
- 스파크는 S3에서 직접 읽을 수도, DB를 통해 읽을 수도 있다.
- 비용에 주의하면 좋다.
2) 엔진
- 쉽게 말해 컴퓨터를 빌리는 것
- 단일 기기를 빌릴 수도 있고, 여러 대를 빌려쓸 수도 있다.
- 접속은 보통 ssh를 이용하고, vscode를 이용하면 좀 더 편리할 수 있다
3) 데이터베이스
- 왜 데이터베이스를 사용하나요?
- 데이터 공유: 데이터베이스는 여러 사용자가 동시에 접근하여 데이터를 공유할 수 있다.
- 데이터 보호: 데이터베이스는 데이터를 보호하기 위해 다양한 보안 기능을 제공
- 데이터 검색: 데이터베이스는 데이터를 쉽게 검색할 수 있도록 인덱싱 기능을 제공
- 데이터 백업과 복원: 데이터베이스는 데이터를 백업하고 복원하는 기능을 제공하여 데이터 손실을 방지함. 이를 통해 중요한 데이터를 안전하게 보호할 수 있다.
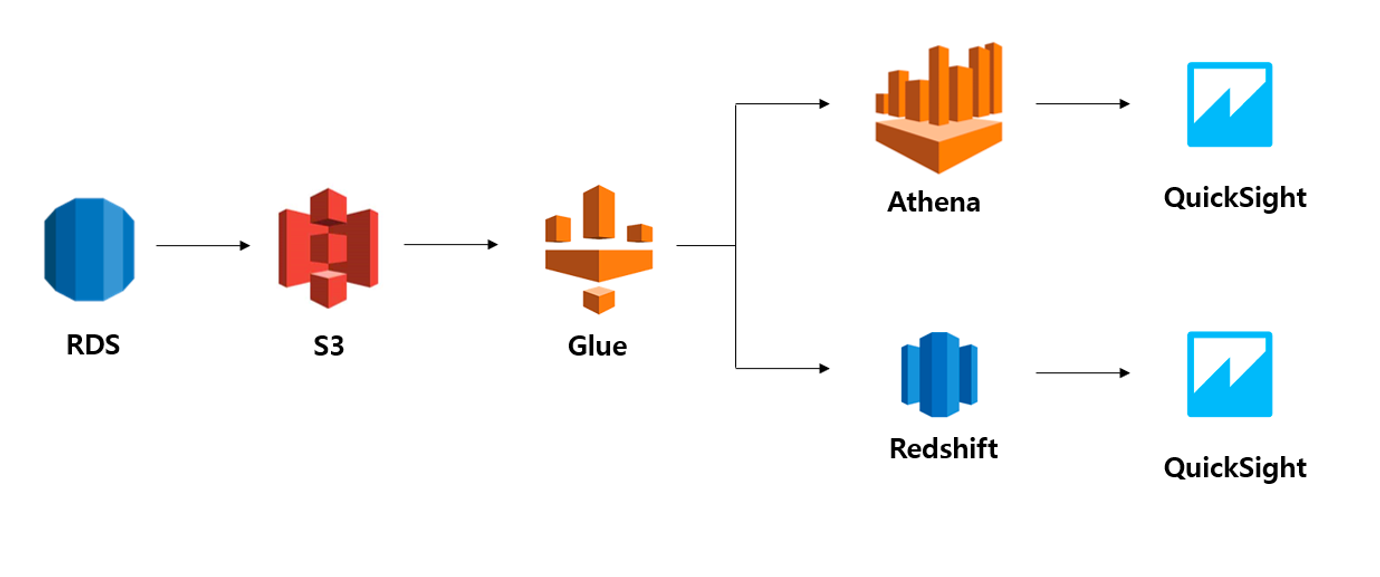
- 수십가지 데이터베이스가 있는데, 서로 다른 세 가지 유형은 아래와 같다.
- 1) RDS: 관계형 데이터베이스
- postgres와 mysql 등 다양한 옵션이 있는데, 보통 엔지니어가 결정한 걸 따르면 된다.
- 인덱싱을 잘 활용하면 좋다.
- 항상 서버가 떠 있어야 하며, 그렇기 때문에 그 비용이 나간다. (가장 저렵 기본 월5만~수백수천)
- 2) Athena: S3에 있는 데이터를 직접 간편하게 분석할 수 있는 대화형 쿼리 서비스
- 보통 S3에 있는 데이터와 연동
- Serverless라고 하여, 쿼리를 운용할 때만 잠시 기기를 빌려 연산한 뒤 다시 반납. 따라서 사용하는 만큼 비용 지불하기에 비용이 저렴한 것이 보통입니다
- 바로 Spark와 연동할 수도 있다
- 3) Redshift: 빠르고 강력한 데이터 웨어하우징
- 구동을 위해서는 클러스터(여러 대의 컴퓨터)를 구성하여 운영해야 한다. 비쌈
- 복잡한 연산에 조금 더 효율적
- 역시, Spark와 연동할 수 있다
아키텍쳐 예시
EMR
- 테라, 페타바이트급 이상의 데이터 처리, 대화식 분석 및 기계 학습을 위한 빅 데이터 솔루션
- AWS에서 Spark를 사용하면, 보통 EMR을 이용
- 직접 운영하는 건 여기서 다룰 난이도가 아니며, 분석가가 할 가능성이 낮음
'SPARK' 카테고리의 다른 글
| [SPRAK] 스파크를 최대한 안쓰기 위한 방법 (Sampling,분할처리,Dask,자동화) (0) | 2024.07.18 |
|---|---|
| [SPARK] 병렬 처리, 분산 처리, Vectorize, CPU, GPU,Joblib (1) | 2024.07.18 |
| [SPARK] 파일 유형, I/O (0) | 2024.07.15 |
| [SPARK] (중요)파이썬과 데이터 - RAM, Disk, CPU, Data type (0) | 2024.07.15 |
| [SPARK] SPARK란? 사용이유 (0) | 2024.07.15 |


